
爬虫以及反爬虫是无休止的技术对抗,严格来讲其本质就是成本对抗,不是不让爬取,而是让爬虫成本远高于对应收益成本。转换到甲方视角,如何提高恶意爬虫方的爬虫成本和如何降低防守方的防护成本是实际工作中的重点。
流量分类大致可以分为几类
- 正常用户流量:流量源来自各类正常用户,行为也属于正常范畴内的各类流量
- 善意爬虫流量:类似谷歌搜索引擎,用于收集互联网的信息展现给普通用户
- 恶意爬虫流量:各类恶意请求流量,比如出行行业的实时获取对方机票,车票,各类漏洞扫描器的实时扫描等
- 无意识流量:未受控制的爬虫长期驻留在网络中,毕业期大学生毕设获取所需数据等
理解爬虫技术(以Python脚本为例)
作为爬虫方,我们获得对应数据进行存储即可完成目标,所以不如简单理解成我们控制pc发送数据包至主机,从返回包中解析数据即可。所以开始编写脚本,用Python纯因为第三方库多,即开即用,但是采用Golang写爬虫后发现效率更高,也推荐使用协程作并发。
是否能够完成爬虫任务的两个根本点
- 能否正常请求数据
- 能否解析数据并进行存储
一个简单脚本,执行后会获取百度的首页内容并且在本地生成一个baidu.html文件。Tips: PyPI中会有很多个投毒包,比如request,这里是requests。
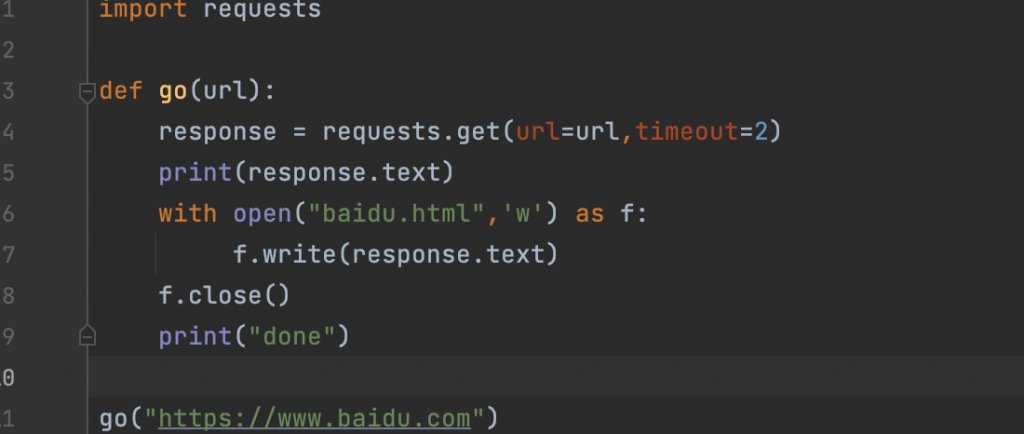
打开本地html文件后发现,和我们正常用户的视角区别很大,除了图标,其他都变成了我们人眼无法识别的字符串,所以问题出在第二步,解析数据中,很明显这也是百度的反爬虫策略之一,后面会详细记录。这就是一个爬虫基础的过程

爬虫实践
对照爬虫任务的两个核心点来看(极大部分的反爬策略都在数据请求过程中设置难度)
按照我的思路实现一个有门槛的爬虫程序,可能需要包括以下几点(实则是不同站点的策略不一致,需要花很多时间进行踩点和试错)
- 正则/xpath/BeautifulSoup工具的适当使用
- 有效的IP代理池,用于触发风控被锁IP后时刻切换。风控侧包括时间,资源被索取量,数据加载量等
- 验证码对抗,常规的灰度识别,依靠打码平台,或者百度api进行图片识别输入,滑块验证码依靠selenium进行js的拖拉操作,加减乘除法验证码,再有的参考字节的拖拉图对其等
- JS逆向。js文件加密通信http包,这是比较花时间的过程,需要主动逆向js文件查看如何加密的,然后再利用第三方库在python中实现加密。
- 数据加密+数据水印。以字体映射为例,这也是目前遇到比较恶心的情况,每次获取数据后映射方式都不一样,参考国内的电影平台。还有就是数据水印,如果被爬取数据中含有防守方水印,但是没有清洗成功仍然被用于业务,可能直接法务上门
- 分布式爬虫实践,这也是我想学习的,未来漏扫相关可能用得上
- 再深入点的就会涉及移动端逆向相关,比如某些没有web端的外卖平台,这里不再提及(因为不会也没做过)
优秀的工具是必不可少的,我也尝试使用过Scrapy,这类似的工具只需要我们将重点放在明确字段即可开心的进行爬虫工作,而且可以灵活的调节并发量,通过xpath代替正则更适合我们定位数据,但是场景受限,所以有一些开发者在此基础上开发了更多的爬虫工具
反爬虫实践
反爬是远远大于爬虫的,不仅要考虑到如何防守,最重要的还是需要考虑到如何不影响业务运行和用户体验,毕竟业务为主,不能错杀。
检测手段
- 请求包中的特殊字段作为特征识别,例如不带header的请求,UA与浏览器指纹不符的请求等,这部分堆特征即可,没什么可以说的
- 爬虫工具selenium,Puppeteer等特征识别,网上大部分是通过无头浏览器去模拟用户,实则全是特征。以selenium为例,通过对比正常和测试浏览器的检测结果发现,直接爆红的特征太多了
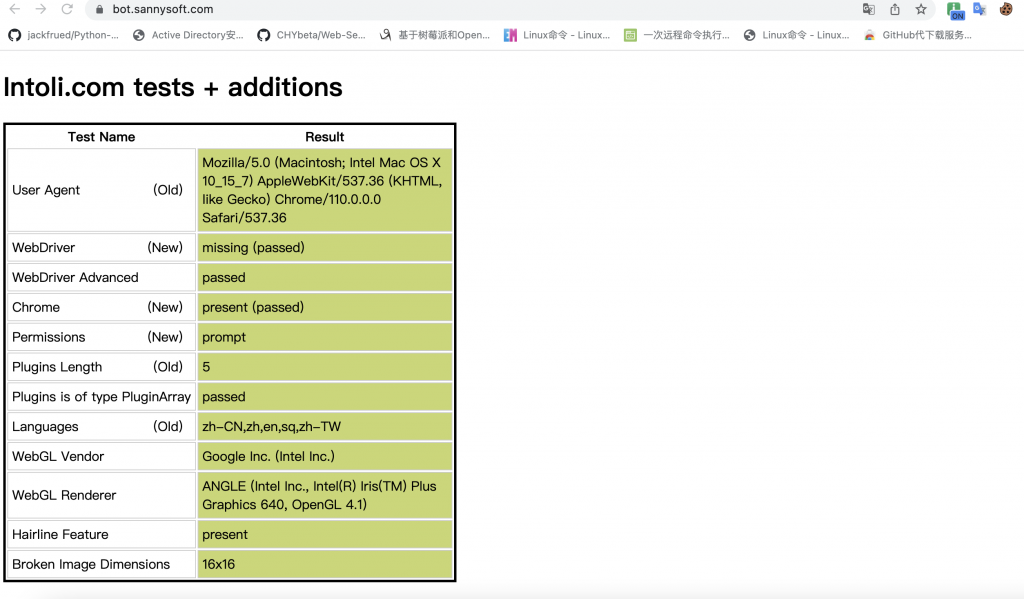

这里的检测是JS检测windows.navigator对象的特征来判断是否是驱动浏览器,所以同样的我们在启动浏览器时可以尝试注入js脚本,用以覆盖检测,这里调用driver.execute_cdp_cmd去执行js,js内容只需要更改window.navigator即可,三个特征识别分别为True,False,Undefind。正常浏览器显示为false,其余特征类似


嵌入js后发现,这个简单反爬即可绕过,但是chromedriver还有其他的特征…..要相信职业反爬的人会比业余选手更加精通chromedriver特征,也不要挑战公司法务部门

- 字体映射等方法混淆数据等方法。这里参考猫眼电影,字符集是随机的,每次都需要重复下载字体文件后去做字符映射….,很烦重复体力活,这部分的文档可以参考文字字符映射,https://blog.csdn.net/fdipzone/article/details/68166388,因为中文文字过多不适用字符映射,所以只有数字以及英文字符会用到这部分技术。这是一个会提高爬虫方数据解析成本的方法
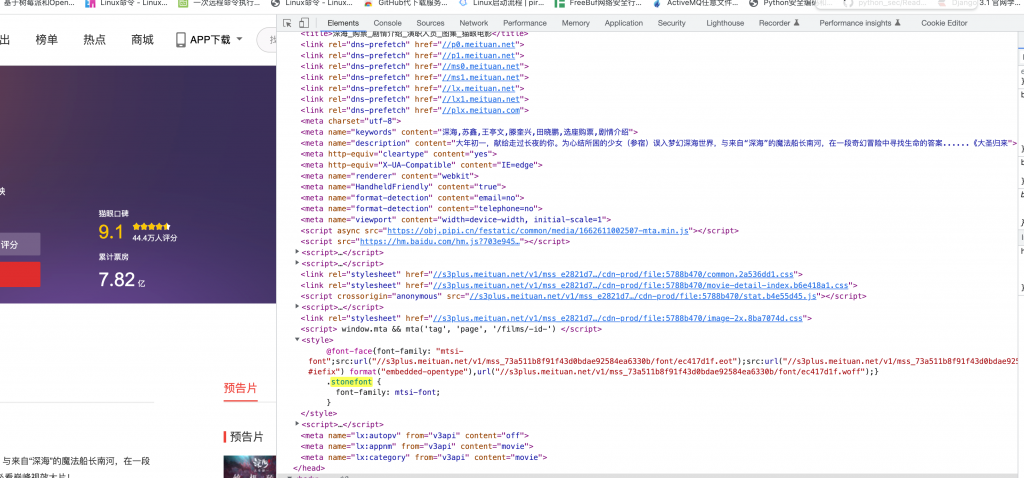
这里直接定位到stonefont去,.woff后缀即是字体文件,通过下载字体文件和数字进行对比即可,时间消耗太多……
页面刷新后的woff又会不一样,所以对于小规模的实时数据获取,我们可以尝试其他方法,类似图片识别,这里我尝试用百度识图,免费

结果也能返回9.1分,计算一下单个返回执行时间,网络正常时时间消耗并不大

- JS反爬相关。这是目前来说应用最多的反爬策略,包括不限于前端对数据进行加密,用户行为特征识别,滑块识别等,一个简单case,检测用户鼠标操作,直接瞬移光标即可认为机器行为。之前为了提高团队效率(查询安全设备信息每次,输入账户密码,等待系统加载,数据加载,筛选等花费了大量时间),写过用于提取信服行为管理系统/威胁情报查询的工具,就遇到了这个问题,js加密+时间戳。逆向js是一个长时间的工作,列举个常见场景,打开调试后出现反调试,最简单的方法就是直接根据callback堆栈回溯函数,重新定义即可,或者对此js打上断点也可以。
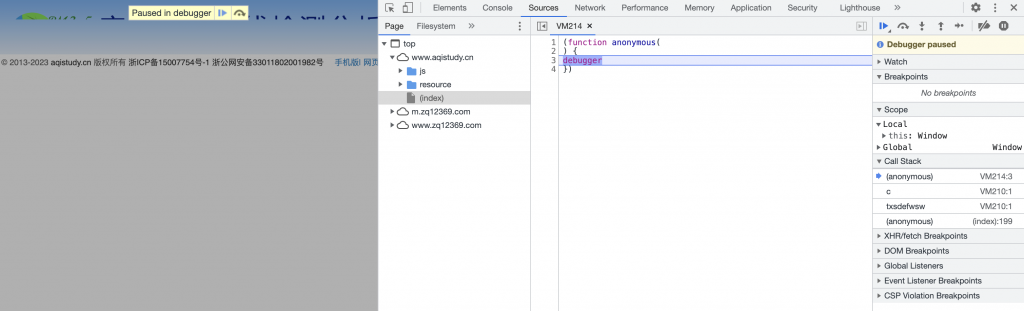
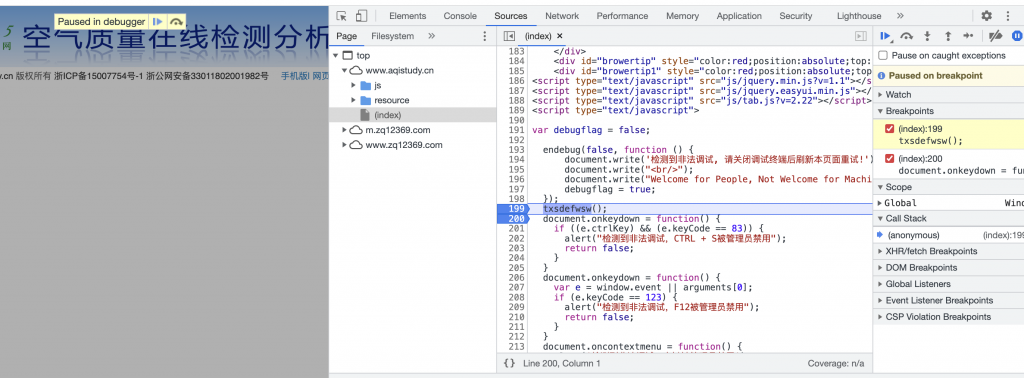
亦或者是在console进行函数替换即可
- 威胁情报+蜜罐配合。可以参考阿里云的文档(实际产品功能不一定好),还是不熟悉业内的实际选择。威胁情报涉及到威胁ip,黑手机号,威胁用户等。蜜罐则是对这部分的威胁情报进行反制,匹配到爬虫行为后在数据中加入大量垃圾数据或者直接返回错误数据

这里通过爬虫和正常用户访问显示不一样的数据结果
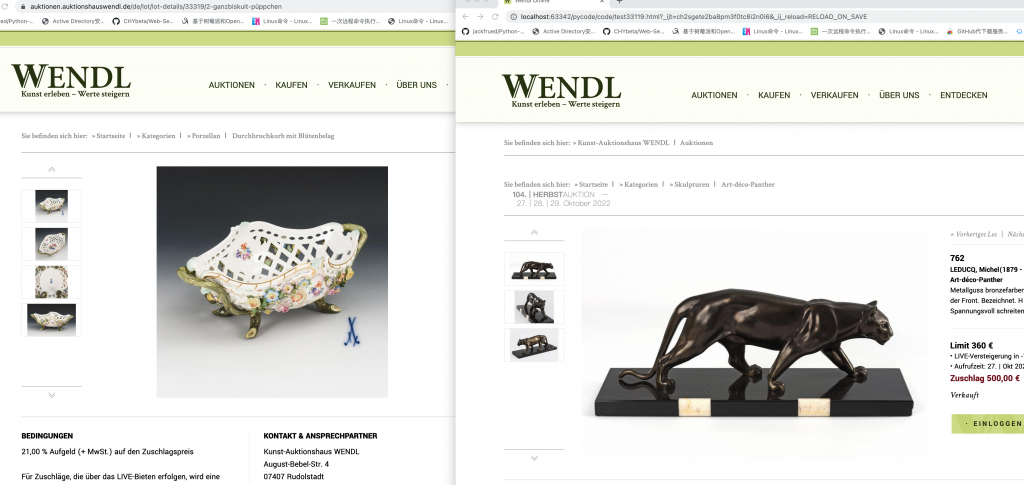
- 最后则是依靠更高级的算法,这一部分就需要对应的专业人去做了。爬虫的过程是长时间的循环遍历接口或者html进行数据获取,所以可以把这一过程进行展示
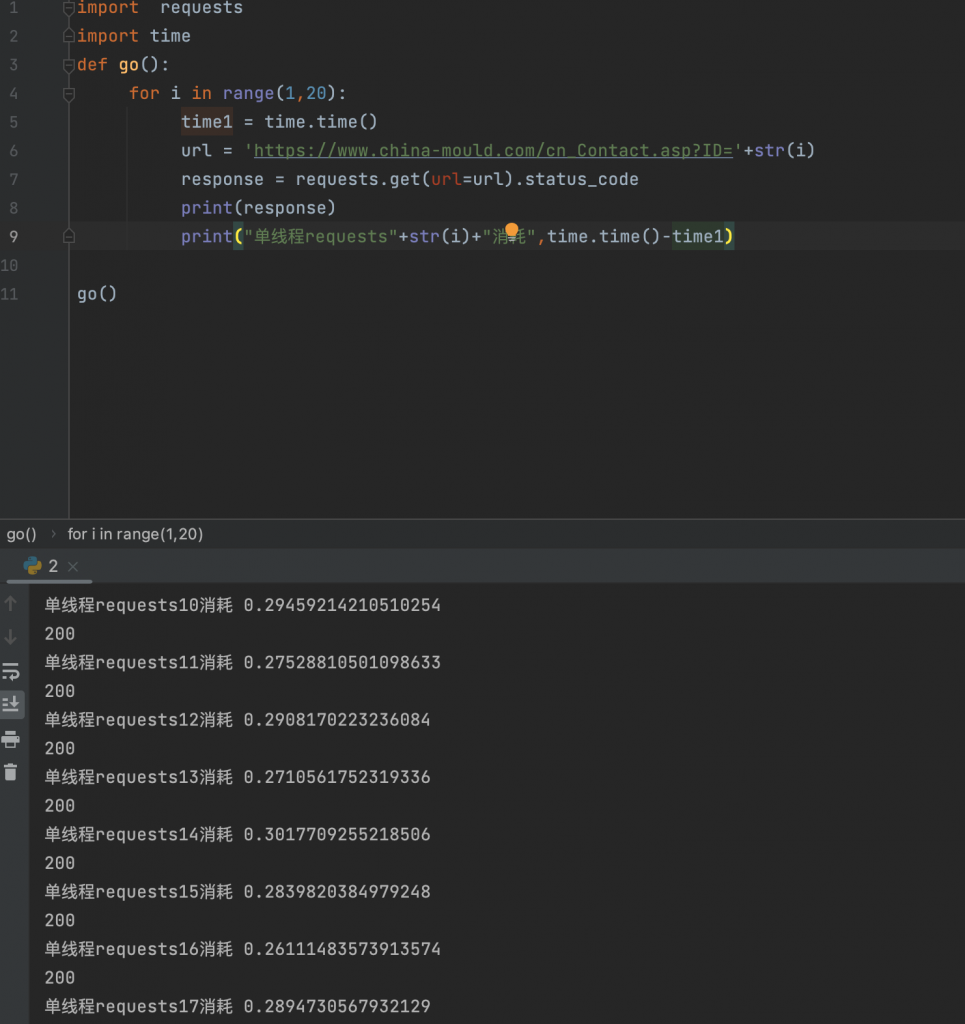
可以直观看到,在单线程爬虫进行任务时,网络波动并不大,并且会趋于一个较稳定的时间,所以可以这样看待
行为分析 = 访问时间 + 访问路径 + 访问请求 + 获取数据 ,多个行为组合进行判断

- 第二个是基于资源利用的角度,如图所示。站在服务器的视角我们可以通过这种方式进行判断爬虫就是,某个ip对于服务器上的数据获取率是否在正常范围内,可能存在丢包行为,这一部分也需要考虑一下。但是我不知道如何如何将这个想法应用于实际生产环境中,毕竟渗透才是主业,接触不了这些东西
