
前言
前两天Docker Hub出了一件事,创建了开源组织仓库的用户都会收到一封邮件,如果不付费就会关闭访问权限,清除对应组织镜像。白嫖用户比如 我瑟瑟发抖,没准后面个人都会进行收费,而且还暂时找不到更好的的镜像托管方式….
云原生技术是一套完整的实践方案,也可以算是方法论,理论技术可以参考CNCF,实际生产技术代表包括容器,服务网格,微服务,声明式API等,当然在实践这套方案的前提就是容器技术能够有效提高工作效率,交付速率,让用户不在烦恼在基础环境配置中。起初PaaS能够出现,就是因为应用托管能力(可以参考https://www.redhat.com/zh/topics/cloud-computing/what-is-paas),不过打包适配云环境过程过于折磨开发人员….
容器的本质
容器本质是物理机上的一个被严格管制的进程,类似于沙盒隔离环境。对于大部分的容器来说,Cgroups和Namespace技术是不可或缺的,而Docker也只是在这基础上实现的工具,真正让Docker出圈的核心能力是Docker镜像功能
开始
Cgroups和NameSpace是有一些抽象的,实践中再去理解会相对容易一些。我的环境是MacOs+Docker CE 20.10
让容器先跑起来
安装Docker后开始run一个基础容器,这里直接run无需pull(如果Docker发现本地不存在此镜像就会去dockerhub中进行搜索后主动pull公共镜像)
% docker run -it busybox /bin/bash
/#whoami
root参数 设置类似 -it都可以通过docker 官方文档查看,这里-it是为我们分配一个终端TTY,这样作为用户就可以与容器进行交互了,/bin/sh就是我们启动的第一个程序,还有-p 端口设置,–name等参数设置。
在这里在执行一次ps命令后发现,当前只在运行/bin/sh 和 ps,这就已经和我们的物理机进行隔离操作了(可以新开一个终端输入ps进行对比)
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
16 root 0:00 ps
/ #实现这个隔离的措施就是Namespace,相当于轻量的虚拟化隔离。我们知道在Linux中通过Clone()去实现进程创建(Linux中的进程是通过线程实现),而Namespace只是Clone()参数设置中的一个可选项-CLONE_NEWPID,亲身经历最好是在windows进行编译运行
int pid = clone(func,stack_size,CLONE_NEWPID | SIGCHLD,NULL)这里我重启一个tomcat镜像改名为t1,我们可以通过几种方式查看这个容器进程运行在物理机上的Pid,docker top <contain_id>,或者是docker inspect t1
docker inspect t1 | grep Pid
"Pid": 2553,
"PidMode": "",
"PidsLimit": null,docker top t1
UID PID PPID C STIME TTY TIME CMD
root 2553 2527 1 16:19 ? 00:00:02这里的PID和PPID分别对应了容器进程在物理机上的pid和容器进程在物理机上的父进程Pid,所以到这里大概就能明白,容器是一个增加了Namespace限制的普通进程,而Docker更类似于辅助型选手, 以编排,辅助形式进行工作

centos7中默认配置了unshare工具,使用unshare可以实现创建和访问不同类型的namespace
$ unshare --pid --fork --mount-proc /bin/bash
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 117648 3304 pts/0 S 14:56 0:00 /bin/bash
root 29 0.0 0.0 156500 1868 pts/0 R+ 14:57 0:00 ps aux容器的隔离与限制
对这些容器进程负责是宿主物理机本身,而不是虚拟机中的OS,Namespace是宿主机上的进程限制,所以隔离与运行都是由宿主机直接负责
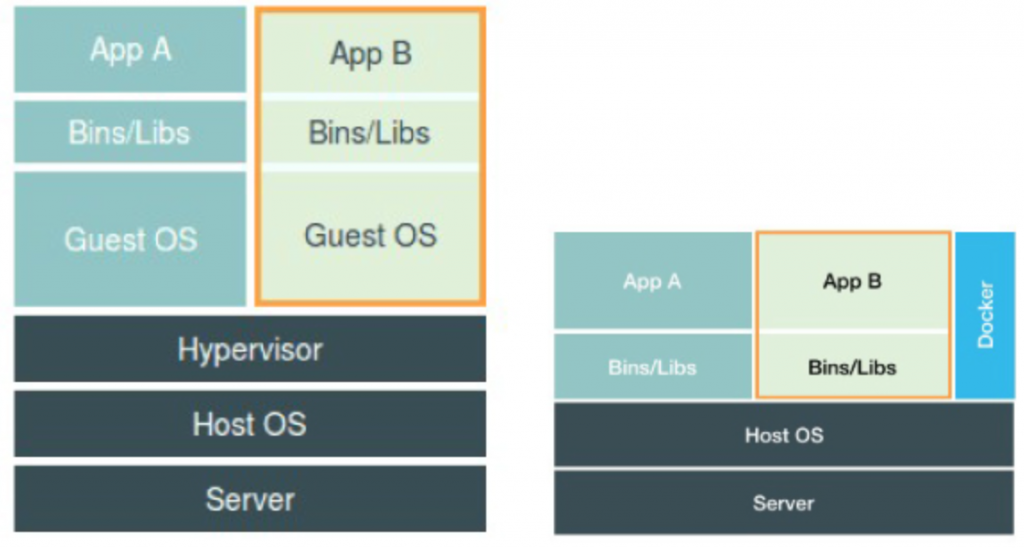
但是就会出现一些新的问题,多个容器共用一个操作系统内核,虽然可以通过Mount Namespace 挂载不同系统文件,但是不能改变宿主机内核,所以在Windows运行Linux容器是行不通的,必须依靠Docker for windows或者虚拟机的形式运行
对比虚拟机和容器可以发现,容器的优势就是效率和性能,常规的虚拟机会自身就会占用较高的内存,用户在虚拟机中执行的操作又需要虚拟化的os,软件等进行处理,又会增加更多的损耗。但是作为运行在物理机上的进程就会不可避免的存在一些安全问题,比如隔离限制的不确定性,Docker只使用了大部分的Linux内核Namespace,还有少部分比如系统时间,Cgroups根目录等,如果容器进程隔离限制没有做好,会直接造成容器逃逸影响到物理机环境
namespace作用只是让进程的视野在namespace的世界中,真正做限制的是Cgroups
Cgroups 是Linux内核的一个功能,实现限制进程或者进程组资源(比如CPU/内存/IO等),它的实现依赖于三个核心:子系统,控制组,层级树
- 子系统:内核组件之一。真正实现资源限制的基础,比如CPU子系统限制CPU使用时间,内存消耗度等
- 控制组:一组进程加子系统。比如一个进程或者多个进程联合使用了一个CPU子系统进行CPU的限制,那这些进程集合+子系统就算是控制组,也就是Cgroup(Control Group)
- 层级树:类似继承后复写父类的一个概念。比如控制组1限制cpu使用20%,控制组2想实现既使用1核,同时也要限制CPU20%使用率,那就控制组2就可以继承1
通过mount命令记录当前挂载的Cgroups信息,可以直观看到常用的子系统,cpu,pids等
mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)创建Cgroups的方式也很简单,直接在对应的子系统下创建目录即可m,这里我去cpu下进行创建
mkdir /sys/fs/cgroup/cpu/m
[root@VM-4-16-centos /]# ls -l /sys/fs/cgroup/cpu/m
总用量 0
-rw-r--r-- 1 root root 0 3月 23 15:19 cgroup.clone_children
--w--w--w- 1 root root 0 3月 23 15:19 cgroup.event_control
-rw-r--r-- 1 root root 0 3月 23 15:19 cgroup.procs
-r--r--r-- 1 root root 0 3月 23 15:19 cpuacct.stat
-rw-r--r-- 1 root root 0 3月 23 15:19 cpuacct.usage
-r--r--r-- 1 root root 0 3月 23 15:19 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 3月 23 15:19 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 3月 23 15:19 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 3月 23 15:19 cpu.rt_period_us
-rw-r--r-- 1 root root 0 3月 23 15:19 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 3月 23 15:19 cpu.shares
-r--r--r-- 1 root root 0 3月 23 15:19 cpu.stat
-rw-r--r-- 1 root root 0 3月 23 15:19 notify_on_release
-rw-r--r-- 1 root root 0 3月 23 15:19 tasks可以看到创建目录后生成了许多的文件,大部分都是一些配置相关,比如cpu.cfs_quota_us代表某一阶段cpu的时间总量,初始值是-1,按照需求进行调整即可,比如要限制一个核,就写上100000即可,然后再去tasks中写入进程ID,多个进程多个ID进行添加即可
不需要使用的时候,直接rmdir该目录即可
Docker创建容器也是一样的方式,比如 docker run -it -m=1g –name=docker_tomcat tomcat ,设置内存为1g,也可以按照同样的方式去对应的目录查看相关信息
这里会有一个坑点,有些机器会提示 /sys/fs/cgroup/cpu/docker 没有这个文件或目录,这个时候就需要手动排查一下cgroups v1和v2
到这里,容器大概就是如此,还有一部分涉及到关于chroot和rootfs相关的不再记录,理解容器完全足够用了,所以现在大概可以理解Docker的工作原理了
- 开启进程设置namespace
- 设置对应Cgroups
- 切换进程根目录chroot
容器镜像的层次
所谓的镜像也就是一个对应资源的rootfs,也就是根文件系统。输入inspect后查看对应镜像文件
$ docker image inspect nginx
Name": "overlay2",
"Data": {
"LowerDir": "/var/lib/docker/overlay2/8ce066677f80c6883acf6880bc95289cf84cec0603508e5f2ffac191ae91cb3c/diff:/var/lib/docker/overlay2/90dfa78c9c61718ad614c8670bdc47fbeac4693c71c5bd597792b648c1aa7496/diff:/var/lib/docker/overlay2/a8f8b07acd5efbea9e826196277e74b43d348b61abb8978cfe874ac6451f36e9/diff:/var/lib/docker/overlay2/30dc59869e2d94bd77fa13024feaa726d3809fd269e3f1fed3a77754e1076f3e/diff:/var/lib/docker/overlay2/b6e80e0fced6de6a8229299b8885beceeb66f5850dd91e7523464caca0e75c0a/diff",
"MergedDir": "/var/lib/docker/overlay2/782b4ec4601ba09de46ce76606a0a51b5ced0be9ac7d2a9117035ed2c9beb079/merged",
"UpperDir": "/var/lib/docker/overlay2/782b4ec4601ba09de46ce76606a0a51b5ced0be9ac7d2a9117035ed2c9beb079/diff",
"WorkDir": "/var/lib/docker/overlay2/782b4ec4601ba09de46ce76606a0a51b5ced0be9ac7d2a9117035ed2c9beb079/work"
....
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:650abce4b096b06ac8bec2046d821d66d801af34f1f1d4c5e272ad030c7873db",
"sha256:4dc5cd799a08ff49a603870c8378ea93083bfc2a4176f56e5531997e94c195d0",
"sha256:e161c82b34d21179db1f546c1cd84153d28a17d865ccaf2dedeb06a903fec12c",
"sha256:83ba6d8ffb8c2974174c02d3ba549e7e0656ebb1bc075a6b6ee89b6c609c6a71",
"sha256:d8466e142d8710abf5b495ebb536478f7e19d9d03b151b5d5bd09df4cfb49248",
"sha256:101af4ba983b04be266217ecee414e88b23e394f62e9801c7c1bdb37cb37bcaa"
]
}
实际上,这个nginx镜像由五层组成,也就是五个rootfs,每一层都是单独的一部分,在docker run后,会通过增量联合挂载在一个统一挂载点
到每一层下去看一下,这里 LowerDir 包含镜像的只读层 ,MergedDir表示Upper和LowerDir合并的结果